

Exemples de scripting
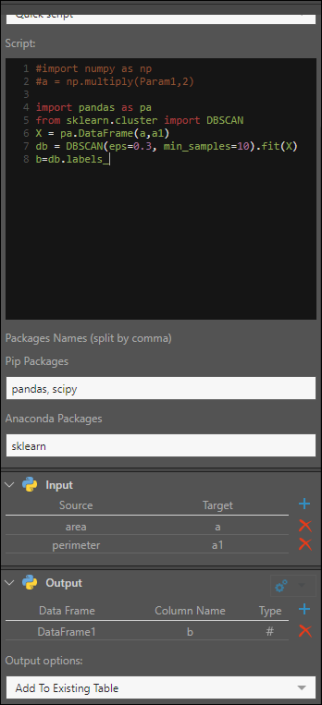
Clustering DBSCAN
Dans cet exemple, une compagnie d'optique veut utiliser le clustering DBSCAN pour grouper les distances entre ses clients.
Elle veut grouper les points de données ensemble selon deux conditions : lorsque leur distance par rapport aux autres points de données du cluster ne dépasse pas 0,3 km ; et il y a au moins 10 points de données dans le cluster.
Importer Pandas en tant que PA .Importer DBSCAN depuis sklearn.cluster.X = pa.DataFrame(a,a1) db = DBSCAN(eps=0.3, min_samples=10).fit(X) b=db.labels_
Régression logistique
Si vous êtes, par exemple, un revendeur avec une boutique en ligne, et que vous voulez prédire le genre de vos visiteurs du site Web en fonction des informations que vous collectez sur eux. Dans cet exemple, nous utiliserons une régression logistique pour produire une prédiction en fonction des revenus et du nombre d'enfants des visiteurs. Les prédictions seront ajoutées à notre tableau sous forme de colonne.
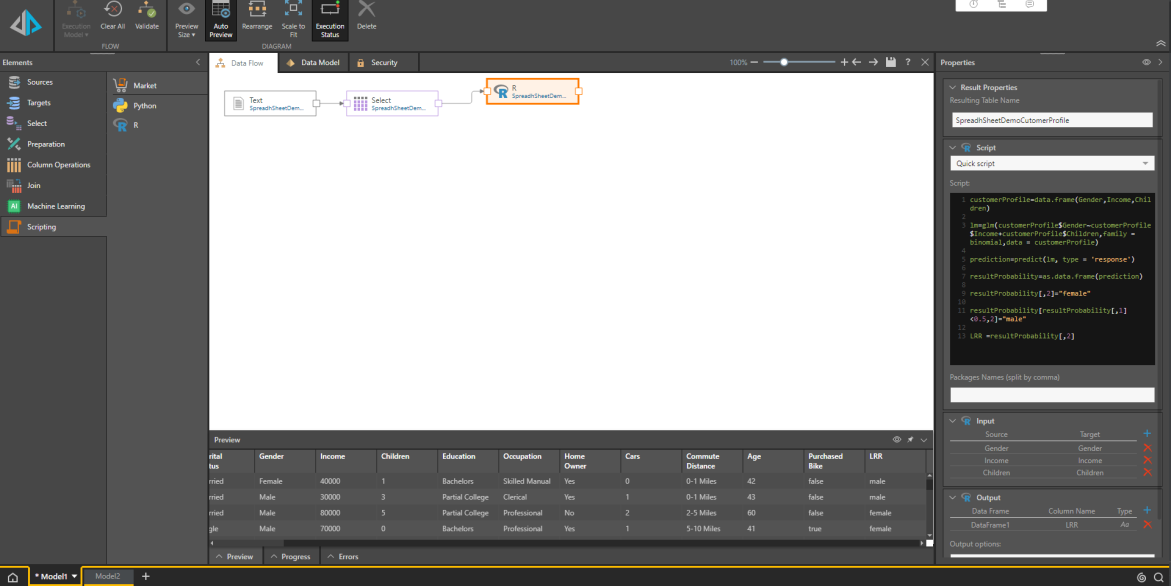
Après avoir ajouté le nœud R, choisissez Script rapide parmi les Options de script dans le panneau Propriétés.
Dans Entrée, cliquez sur le signe plus et choisissez De : Genre, et Vers : Genre. Notez que nous ajoutons une entrée de Genre, afin de pouvoir comparer les résultats avec le genre réel.
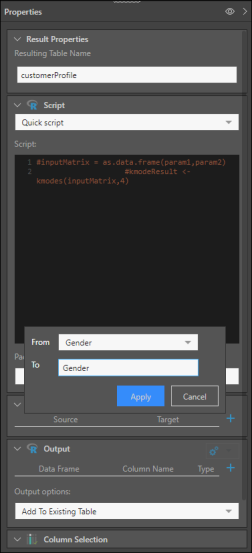
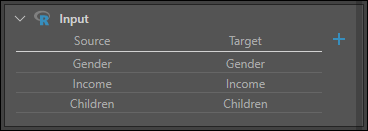
Cliquez sur Appliquer, et ajoutez deux autres colonnes dans Entrée : une pour les Revenus, et une autre pour les Enfants.
Ajoutez le script suivant sans la fenêtre Script :
customerProfile=data.frame(Gender,Income,Children)
lm=glm(customerProfile$Gender~customerProfile$Income+customerProfile$Children,family = binomial,data = customerProfile)
prediction=predict(lm, type = 'response')
resultProbability=as.data.frame(prediction)
resultProbability[,2]="femme"
resultProbability[resultProbability[,1]<0.5,2]="homme"
LRR =resultProbability[,2]
Cliquez sur le signe plus sous Sortie pour ajouter la colonne de sortie :
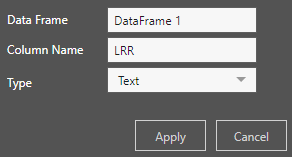
Demandez un aperçu de la table pour voir la nouvelle colonne.
Accueil | Table des matières | Index | Communauté d'utilisateurs
Pyramid Analytics © 2017-2019